Jak Riot wykrył awarię?
W pierwszej kolejności w Centrum Operacji Sieciowych zauważono drastyczny spadek liczby gier.
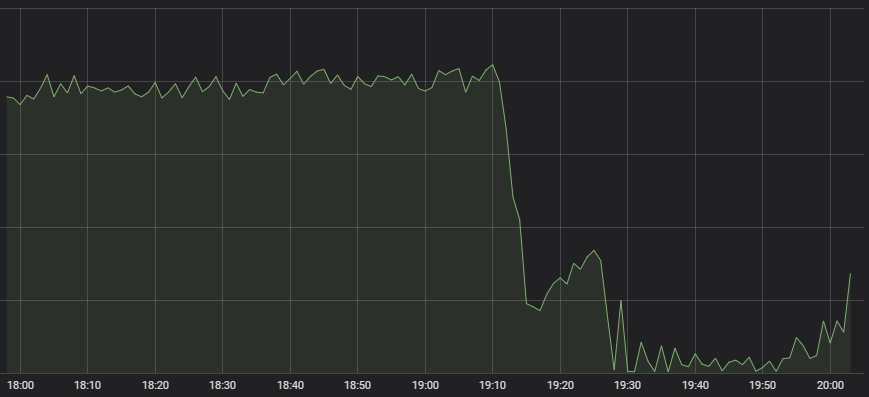
Następnie próbowano zdefiniować, którego systemu (np. dobieranie przeciwników, rozkład obciążenia, serwer gry) dotyczył problem. Było to jednak trudne do określenia – systemy działały poprawnie, jednak docierało do nich niewiele ruchu. Dostępne dane wskazywały na duże problemy w tym zakresie, co widoczne jest na poniższym wykresie, który prezentuje liczbę połączeń przychodzących, które docierają do jednego z hostów kontenerowych Riotu (czyli pojedynczego, wysokowydajnego komputera, obsługującego szereg mniejszych aplikacji potocznie określanego jako “kontener”; to na tych maszynach opiera się cały system umożliwiający funkcjonowanie LoL-a). Dwa z tych hostów otrzymywały zbyt dużo połączeń.
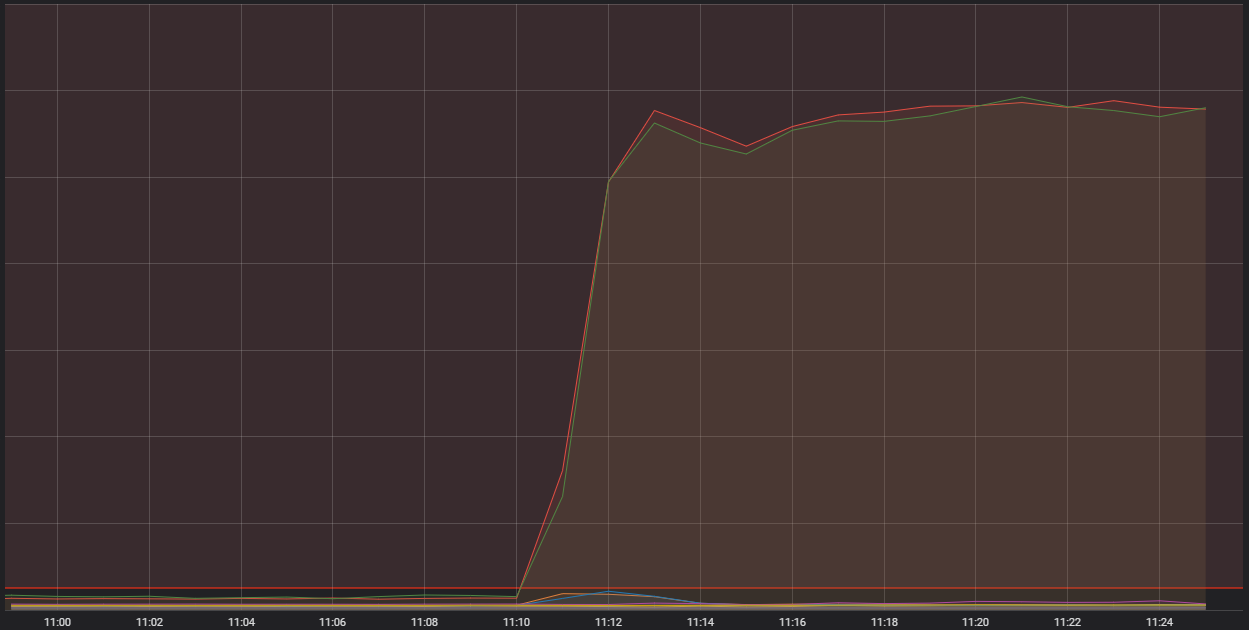
Dlaczego tak się stało?
Problem dotknął szczególnego rodzaju kontenera wykonującego funkcję brzegową (ang. “edge”), której celem jest przyjmowanie ruchu przychodzącego z Internetu, filtrowanie go i przesyłanie do właściwej usługi zaplecza. Pojawiły się gwałtowne skoki obciążenia, które poskutkowały trudnościami z korzystaniem z LoL-a. Przyczyny tych skoków były następujące:
- Zbyt wysoka liczba żądań wysłanych do jednej usługi, co wynikało z tego, że żądanie było zgłaszane w błędny sposób i nie dochodziło do skutku, tylko było cały czas ponawiane.
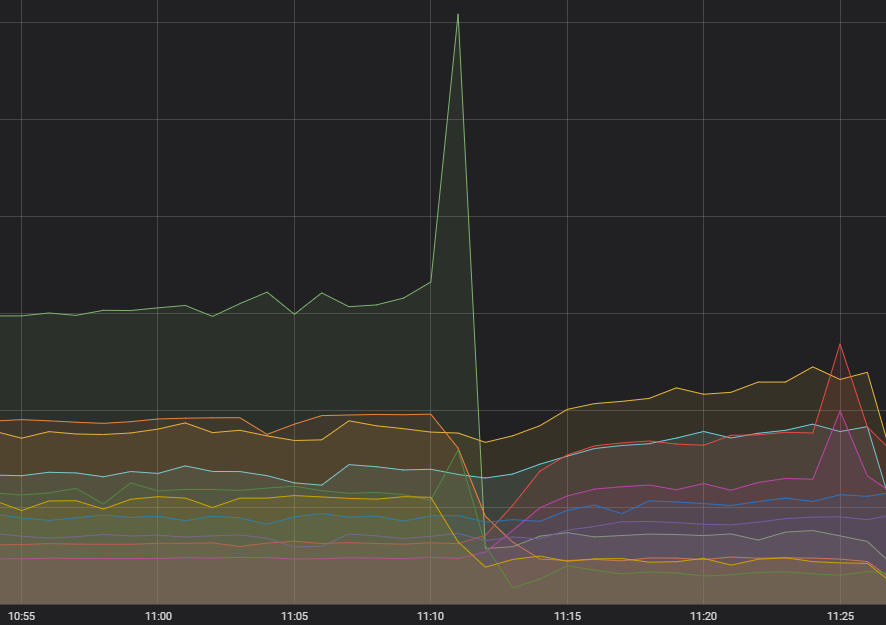
- Problem, w ramach którego dochodziło do interakcji naszego systemu kontenerów z używaną wersją systemu operacyjnego (przeciek pamięci wewnątrz systemu operacyjnego, który – jeśli trwał wystarczająco długo – mógł spowodować zatrzymanie najważniejszych funkcji systemowych). Problem ten jest znany od pewnego czasu i 60% kontenerów otrzymało już ulepszenia z nim związane. Niestety aktualizacja grup w Europie i Ameryce Łacińskiej wciąż trwała.
- Pech.
No i ostatnia rzecz: nie mieliśmy szczęścia. Korzystamy z oprogramowania, które grupuje kontenery w segmenty mieszczące się na pojedynczym komputerze-hoście. Zawiera ono zaprogramowane ograniczenia, które mają oddzielać obciążające sieć usługi brzegowe w zestawie kontenerów przynależących do konkretnego odłamka. Nie mieliśmy jednak wpływu na sytuacje, w których usługi brzegowe z odmiennych odłamków mogły trafić na ten sam komputer, w związku z czym usługi brzegowe z EUW mogły zaleźć się tuż obok usług brzegowych z EUNE. Zwielokrotnienie obciążenia pojedynczego komputera okazało się katalizatorem, który zamienił dwa wyżej opisane problemy w poważny incydent.
W przypadku wszystkich awarii doszło do tego, że kontenery brzegowe z co najmniej trzech odłamków zostały umieszczone w tym samym hoście. Ruch pochodzący z nieprawidłowych żądań, spotęgowany przez pochodzący z wielu odłamków ruch trafiający do tego samego hosta, oraz wyciek pamięci w systemie operacyjnym skutkujący „obezwładnieniem” tego komputera — oto czynniki, które doprowadziły do dysfunkcji odłamka i poważnej awarii.
Jak problem zostanie rozwiązany?
Każda przyczyna może zostać usunięta.
Co już zrobiono?
- Poprawiono kod powodujący wysyłanie wadliwych żądań.
- Zmieniono sposób działania mechanizmu ponawiania żądań w taki sposób, by nie dochodziło do ich kumulacji.
- Zaktualizowano oprogramowanie kontenerowe obsługujące wszystkie odłamki.
- Wprowadzono procedurę alarmową: zawsze będzie dostępna osoba, która będzie miała za zadanie likwidować ręcznie zbyt duże obciążenie.
Co będzie zrobione w przyszłości?
- Usługi brzegowe zostaną przeniesione do zapewniającego równowagę systemu, który będzie w stanie równomiernie je rozdzielać w ramach odłamka.
Rekompensata?
Temat nie został poruszony – co prawdopodobnie oznacza, że jej nie otrzymamy…
